分布式高级篇(一)ElasticSearch和商城首页
ElasticSearch--全文检索
简介
是什么
- ElasticSearch是一个分布式的开源搜索和分析引擎,适用于所有类型的数据,包括文本、数字、地理空间、结构化和非结构化数据
- ElasticSearch在Apache Lucene的基础上开发而成,由Elastic于2010年首次发布,ElasticSearch以其简单的REST风格API、分布式特性、速度和可扩展而闻名
用途
- ElasticSearch在速度和可扩展性方面都表现出色,而且还能够索引多种类型的内容,这意味着其可用于多种用例:
- 应用程序搜索
- 网站搜索
- 企业搜索
- 日志处理和分析
- 基础设施指标和容器监测
- 应用程序性能监测
- 地理空间数据分析和可视化
- 安全分析
- 业务分析
基本概念
关系图
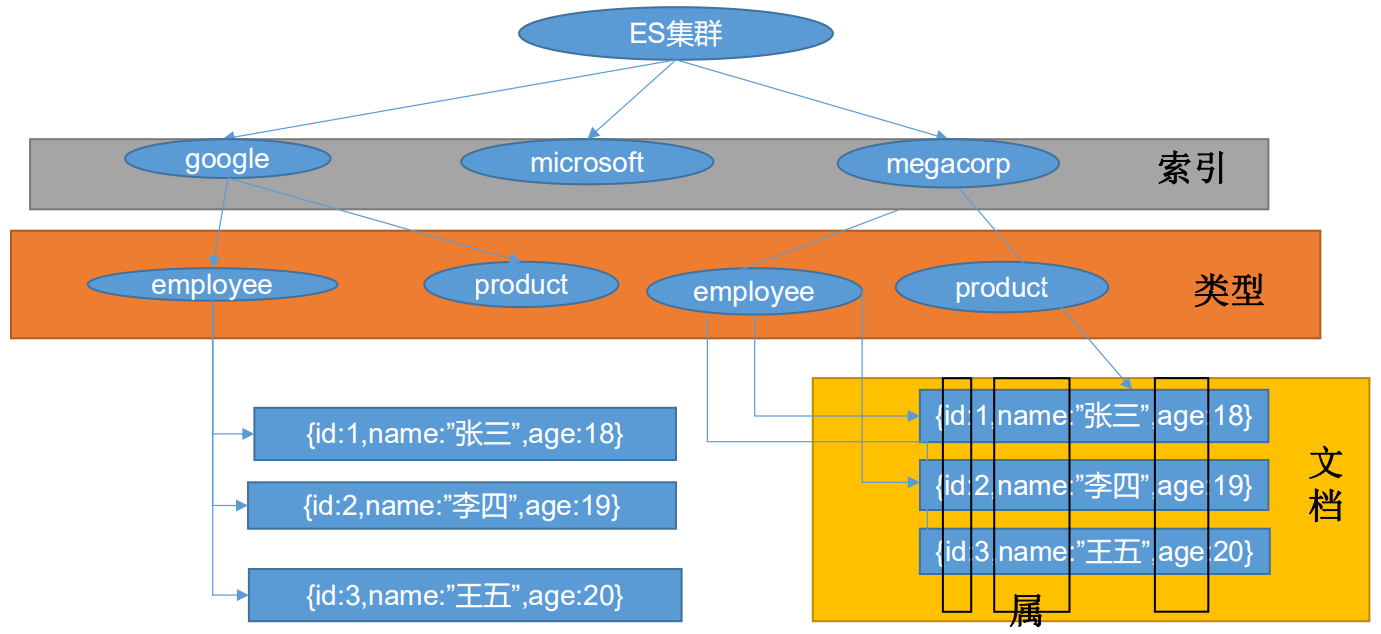
Index(索引)
动词,相当于MySQL中的insert;mysql中插入(insert)一条数据,ES中索引一条数据
名词,相当于MySQL中的DataBase
Type(类型)
- 在index(索引)中,可以定义一个或多个类型。类似于MySQL中的Table;每一种类型的数据放在一起
ElasticSearch7-去掉type概念
关系型数据库中两个数据表示是独立的,即使他们里面有相同名称的列也不影响使用但ES中不是这样的而ES中不同type下名称相同的filed最终在Lucene中的处理方式是一样的
两个不同type下的两个user_name,在ES同一个索引下其实被认为是同一个filed,你必须在两个不同的type中定义相同的filed映射。否则,不同type中的相同字段名称就会在处理中出现冲突的情况,导致Lucene处理效率下降
去掉type就是为了提高ES处理数据的效率
Elasticsearch 7.x
URL中的type参数为可选。比如,索引一个文档不再要求提供文档类型
Elasticsearch 8.x
不再支持URL中的type参数,解决:将索引从多类型迁移到单类型,每种类型文档一个独立索引
Document(文档)
- 保存在某个索引(index)下,某种类型(Type)的一个数据(Document),文档是JSON格式的,Document就像是MySQL中的某个Table中的记录
倒排索引机制
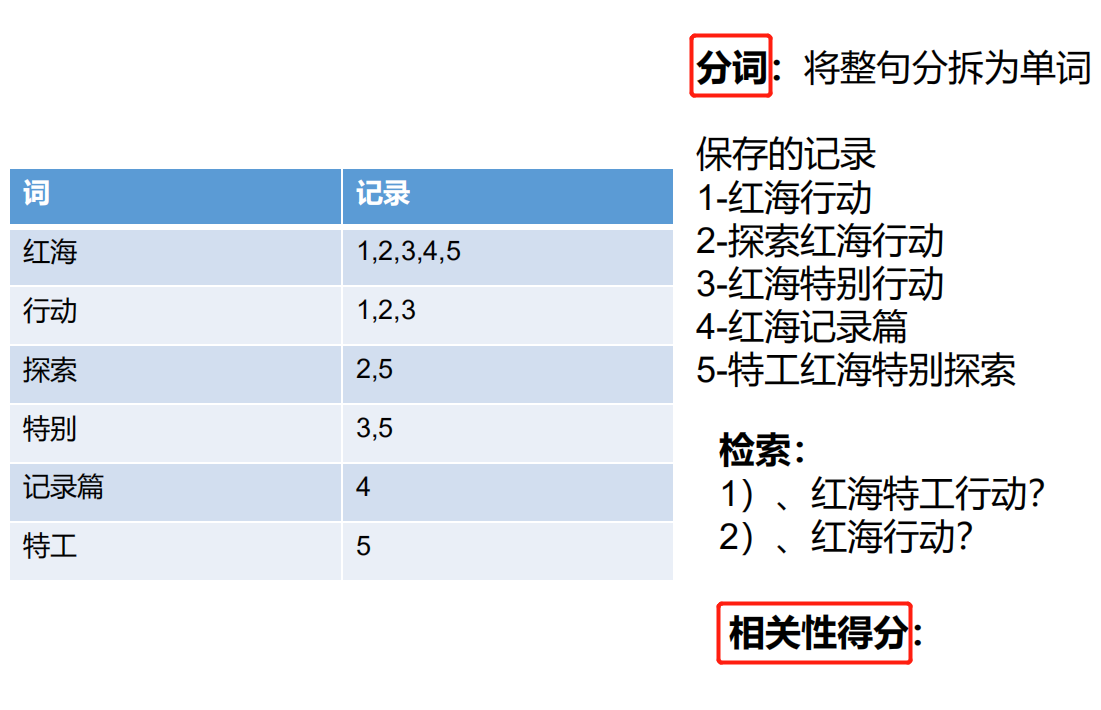
举个简单例子
在MySQL中保存一个数据:正向索引。每一条数据都有一个id对应着;这时如果想要检索一个数据,比如电影表中检索 红海行动
like 红海行动 这时候MySQL会匹配所有记录,看是否有红海行动,这种检索显然是非常慢的操作
而在ES中,在存储数据的时候,同时会维护一张倒排索引表
怎么维护:在存储数据时,首先会进行分词:将整句分拆成单词,比如 红海行动 拆分成 红海、行动、红、海...... 这时候 ES中的1号文档记录的是红海行动,同时倒排索引也维护了 红海、行动 出现在1号文档中
相关性得分:命中的分词个数越多,分越高
Docker安装
安装ElasticSearch 7.6.1
拉取镜像
docker pull elasticsearch:7.6.1运行容器并挂载
启动容器
docker run -d --name es -p 9200:9200 -p 9300:9300 \-e "discovery.type=single-node" elasticsearch:7.6.1将配置文件、数据目录、插件目录拷出来做挂载
docker cp es:/usr/share/elasticsearch/config/ /var/touchAirMallVolume/es/config/docker cp es:/usr/share/elasticsearch/data/ /var/touchAirMallVolume/es/data/docker cp es:/usr/share/elasticsearch/plugins/ /var/touchAirMallVolume/es/plugins/vim /var/touchAirMallVolume/es/config/elasticsearch.yml#添加这2行#设置允许跨域访问http.cors.enabled: truehttp.cors.allow-origin: "*"销毁容器,重新以挂载方式运行
注意:ES默认内存需要2g,虚拟机内存不足的需要设置 ES_JAVA_OPTS,否则会卡死
#销毁docker rm -f es#挂载配置文件docker run -d --name es -p 9200:9200 -p 9300:9300 -v /var/touchAirMallVolume/es/config:/usr/share/elasticsearch/config \-v /var/touchAirMallVolume/es/data:/usr/share/elasticsearch/data \-v /var/touchAirMallVolume/es/plugins:/usr/share/elasticsearch/plugins \-e "discovery.type=single-node" \--restart=always elasticsearch:7.6.1
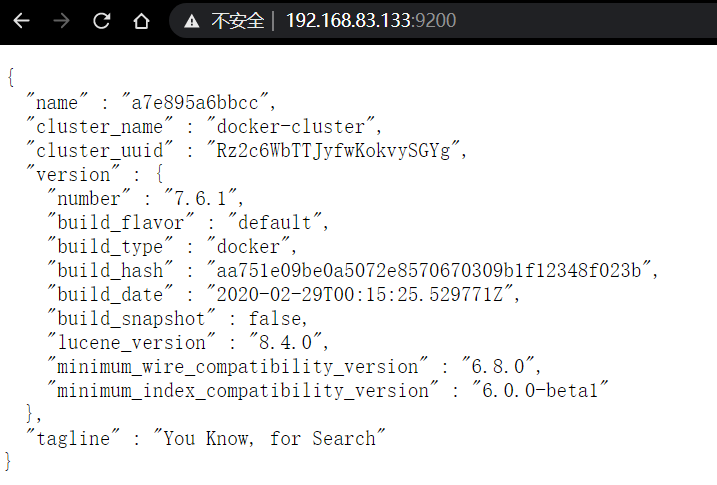
访问宿主机ip的9200端口,查看是否启动成功
安装Kibana 7.6.1
- ES的可视化工具 版本要对应
拉取镜像
docker pull kibana:7.6.1运行容器
先运行容器
docker run -d --name kibana -p 5601:5601 kibana:7.6.1拷出配置文件,后面做挂载
# 拷贝docker cp kibana:/usr/share/kibana/config/ /var/touchAirMallVolume/kibana/config/#修改配置 vim kibana.yml #放开访问地址0.0.0.0#配置es地 src="https://img2020.cnblogs.com/blog/1875400/202101/1875400-20210112100014492-1626896609.png" alt="image-20210102182139475" loading="lazy">挂载运行
# 先销毁容器docker rm -f kibana# 运行容器docker run -d --name kibana \-p 5601:5601 --restart=always \-v /var/touchAirMallVolume/kibana/config:/usr/share/kibana/config \kibana:7.6.1宿主机ip:5601,查看kibana图形化界面
初步检索
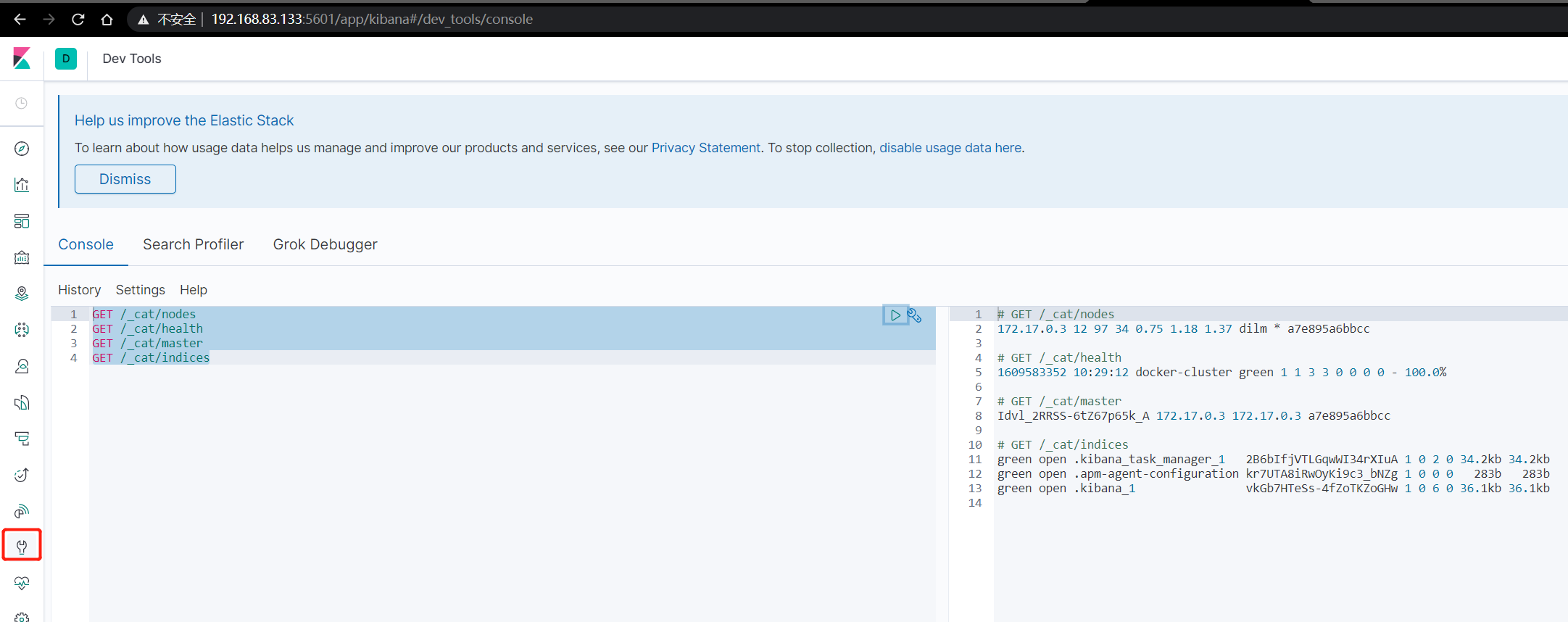
_cat
GET /_cat/nodes 查看所有节点
GET /_cat/health 查看es健康状况
GET /_cat/master 查看主节点
GET /_cat/indices 查看所有索引 类似 show databases;
索引一个文档(保存)
保存一个数据,保存在哪个索引的哪个类型下,指定用哪个唯一标识
PUT customer/external/1{ "name":"touchair"}#发送多次是一个更新操作
PUT和POST都可以
POST 新增:如果不指定id,会自动生成id,指定id就回去修改这个数据,并新增版本号
PUT 可以新增可以修改:PUT必须指定id,不指定会报错,由于PUT需要指定id,一般用来做修改操作
查询文档
查询刚刚新增的数据
GET customer/external/1

更新文档
更新
POST customer/external/1/_update{ "doc":{ "name":"touchair2" }}#或者POST customer/external/1{ "name":"touchair3"}#或者PUT customer/external/1{ "name":"touchair4"}区别:
PUT操作总会将数据重新保存并增加version版本;
POST操作 带_update对比源数据如果一样就不进行任何操作,文档version不增加
POST操作 不带_update 就不会检查源数据,始终更新
- 看场景
- 对于大并发更新,不带update
- 对于大并发查询偶尔更新,带update;对比更新,重新计算分配规则
- 看场景
更新同时增加属性
注意 带_update 需要带 doc 写法
POST customer/external/1/_update{ "doc":{ "name":"post_add_condition", "age":20 }}
删除文档&索引
删除文档
DELETE customer/external/1删除索引
DELETE customer
bulk批量API
批量
POST customer/external/_bulk{"index":{"_id":3}}{"name":"奋斗逼"}{"index":{"_id":4}}{"name":"你他妈卷到我了"}#语法格式:#action 指定要操作的源数据{action:{metadata}} \n{request body } \n{action:{metadata}} \n{request body } \n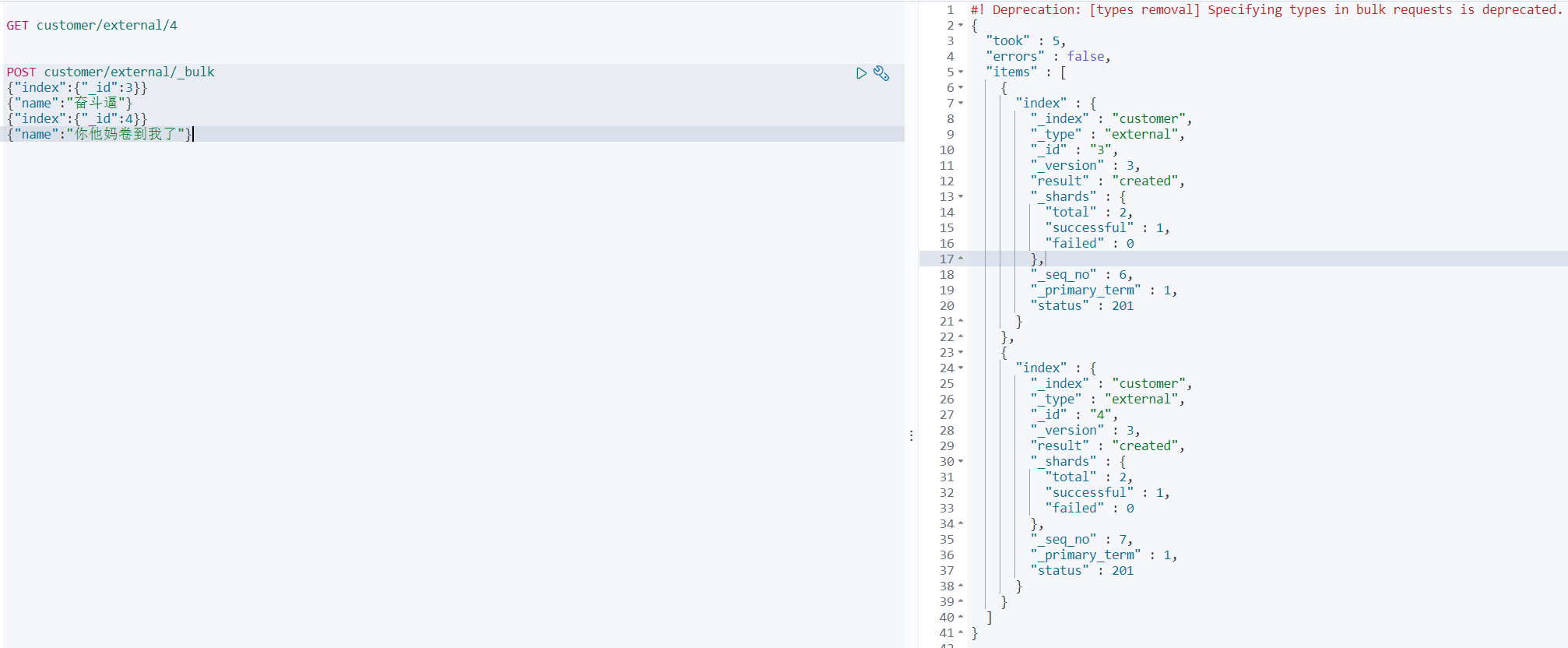
复杂实例
POST /_bulk{"delete":{"_index":"website","_type":"blog","_id":"123"}}{"create":{"_index":"website","_type":"blog","_id":"123"}}{"title":"My first blog post"}{"index":{"_index":"website","_type":"blog"}}{"title":"My second blog post"}{"update":{"_index":"website","_type":"blog","_id":"123","_retry_on_conflict":3}}{"doc":{"title":"My updated blog post"}}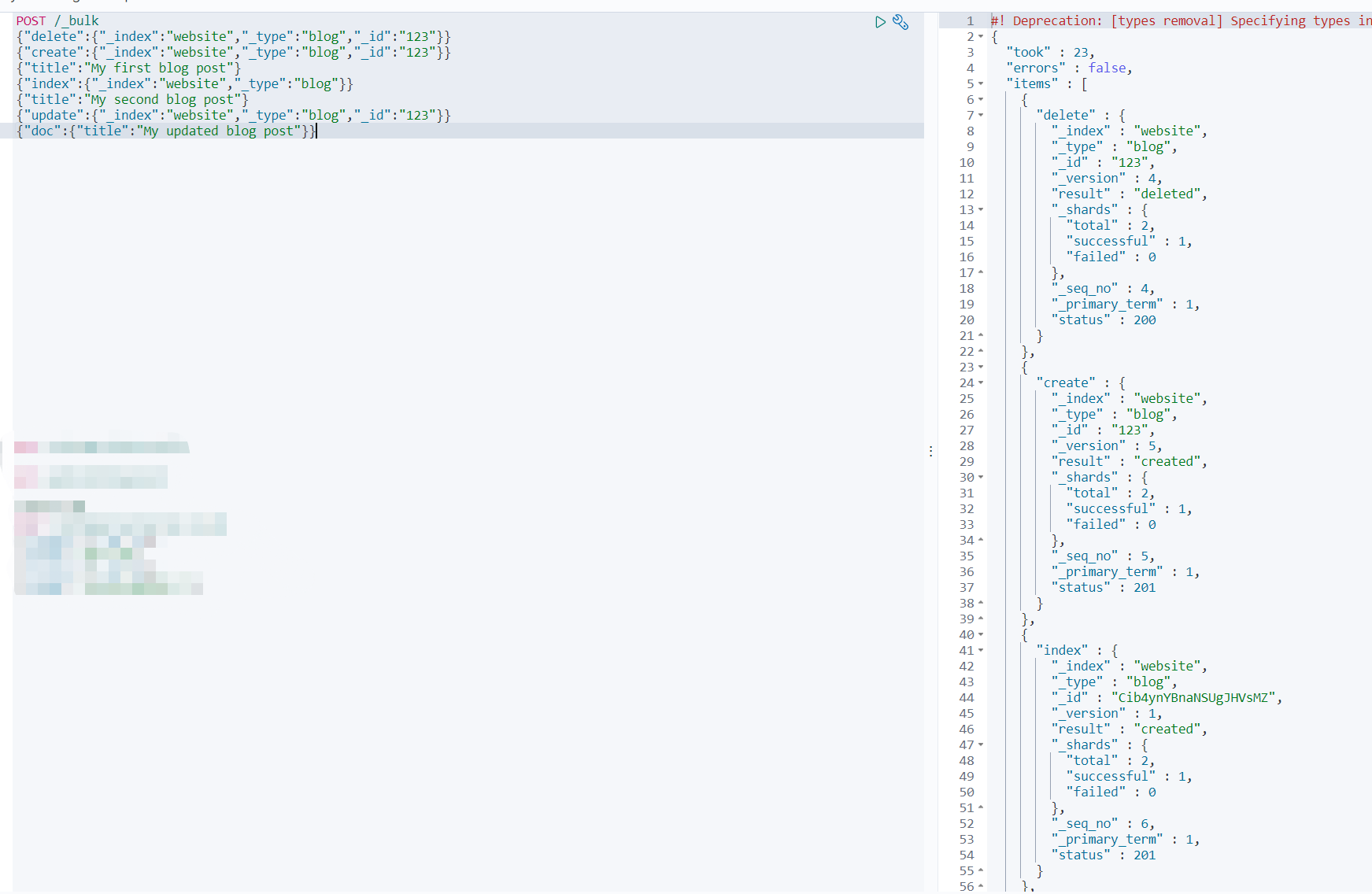
bulk API 以此顺序执行所有的action(动作),如果一个单个的动作因任何原因而失败,它将继续处理后面剩余的动作。当bulk API返回时,它将提供每个动作的状态(与发送的顺序相同),所以您可以检查是否一个指定的动作是不是失败了
样本测试数据
es官方提供的样本数据地址
POST bank/accout/_bulk

进阶检索
- 完全参照官方实例
Search API
- ES支持两种基本方式检索
- 一个是通过使用REST request URI 发送搜索参数(uri+检索参数)
- 另一个是通过使用 REST request body 来发送它们(uri+请求体)
检索信息
请求检索按帐号排序的银行索引中的所有文档
GET /bank/_search{ "query": { "match_all": {} }, "sort": [ { "account_number": "asc" } ]}默认情况下,响应的命中部分包含与搜索条件匹配的前10个文档
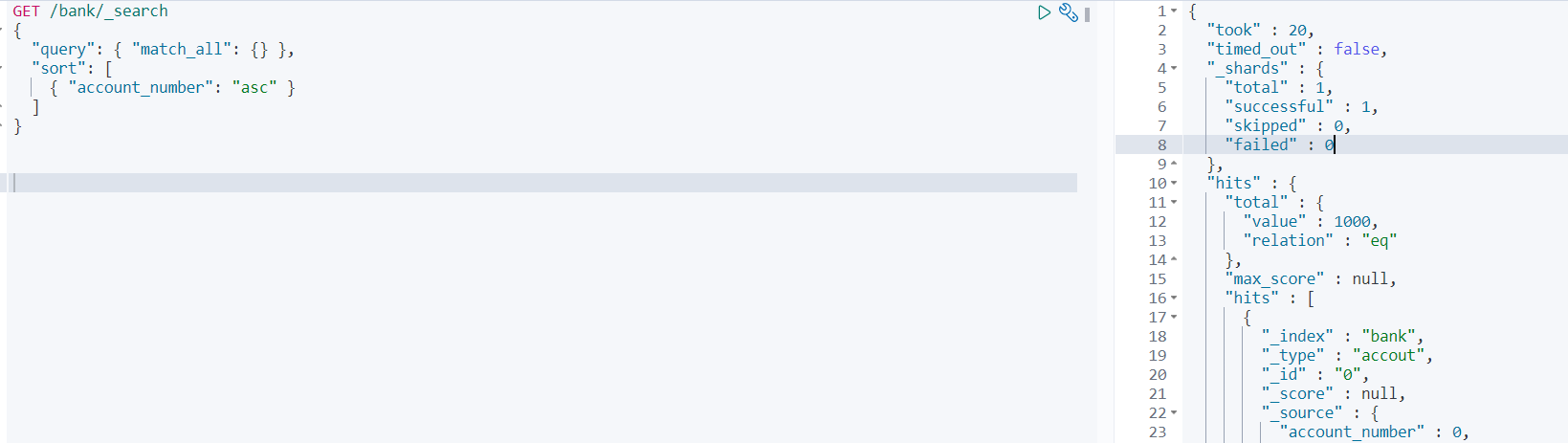
took:Elasticsearch 运行查询需要多长时间(毫秒)timed_out:搜寻请求是否超时_shards:搜索了多少碎片,并分别列出成功、失败或跳过的碎片数量max_score:找到的最相关文件的分数hits.total.value:找到多少相符的文件hits.sort:文档的排序位置(当不按相关性得分排序时)hits._score:文件的相关性得分(不适用于使用match_all)
每个搜索请求都是自包含的: Elasticsearch 不维护跨请求的任何状态信息。若要浏览搜索结果,请在请求中指定 from 和 size 参数
下面的请求会得到从10到19的结果
GET /bank/_search{ "query": { "match_all": {} }, "sort": [ { "account_number": "asc" } ], "from": 10, "size": 10}
Query DSL
基本语法格式
- ElasticSearch提供了一个可以执行查询的json风格的DSL(domain-specific language 领域特点语言)。这个被称为Query DSL。该查询语言非常全面,并且刚开始的时候感觉有点复杂,真正学好它的方法是从一些基础的示例开始的
match(匹配查询)
基本类型(非字符串),精确匹配
GET /bank/_search{ "query": { "match": { "account_number": 20 } }}字符串,全文检索
全文检索按照评分进行排序,会对检索条件进行分词匹配
GET /bank/_search{ "query": { "match": { "address": "Kings" } }}
match_phrase(短语匹配)
将需要匹配的值当成一个整体单词(不分词)进行检索
GET /bank/_search{ "query": { "match_phrase": { "address": "282 Kings" } }}
multi_match(多字段匹配)
state 或者 address 包含 mill
GET /bank/_search{ "query": { "multi_match": { "query": "mill", "fields": ["address","state"] } }}
bool(复合查询)
bool用来做复合查询:复合语句可以合并任何其它查询语句,包括复合语句,了解这一点很重要。这就意味着,复合语句之间可以互相嵌套,可以表达非常复杂的逻辑
must:必须达到must列举的所有条件must_not:必须排除must_not列举的所有条件should:应该满足 当然也可以不满足
GET /_search{ "query": { "bool": { "must": [ { "match": { "gender": "M" }}, { "match": { "address": "mill" }} ], "must_not": [ {"match": { "age": "28" }} ], "should": [ {"match": { "lastname": "Wallace" }} ] } }}
filter(结果过滤)
相关性得分是一个正浮点数,返回到搜索 API 的 _ score 元字段中。得分越高,文档越相关。虽然每种查询类型可以以不同的方式计算相关性分数,但分数计算还取决于查询子句是在查询中运行还是在过滤上下文中运行
并不是所有的查询都需要产生分数,特别是那些仅用于
filtering(过滤)的文档。为了不计算分数ElasticSearch会自动检查场景并且优化查询的执行must、should只有满足条件,就会对对相关性得分提升,must_not则会被当成filter,fliter最大的一个特点就是不会对文档的相关性得分产生影响比较,主要观察结果中的
_score#must GET bank/_search{ "query": { "bool": { "must": [ {"range": { "age": { "gte": 18, "lte": 30 } }} ] } }}#filterGET bank/_search{ "query": { "bool": { "filter": [ {"range": { "age": { "gte": 18, "lte": 30 } }} ] } }}
term(精确查找)
和match一样,匹配某个属性的值。全文检索字段用match,其他非text字段匹配用term
GET bank/_search{ "query": { "term": { "balance": "18607" } }}#加上keyword 进行精确匹配(不会进行分词)GET bank/_search{ "query": { "match": { "address.keyword": "789 Madision" } }}GET bank/_search{ "query": { "match": { "address": "789 Madision" } }}
aggregation(执行聚合)
聚合提供了从数据中分组和提取数据的能力,最简单的聚合方法大致等于SQL GROUP BY和SQL聚合函数。在ElasticSearch中,有执行搜索返回
hits(命中结果),并且同时返回聚合结果,把一个响应中的所有hits(命中结果)分隔开的能力。这是非常强大且有效的,可以执行查询和多个聚合,并且在一次使用中得到各自的(任何一个的)返回结果,使用一个简洁和简化的API来避免网络往返搜索
address中包含mill的所有人的年龄分布以及平均年龄,但不显示这些人的详情GET bank/_search{ "query": { "match": { "address": "mill" } }, "aggs": { "ageAgg": { "terms": { "field": "age", "size": 10 } }, "ageAvg":{ "avg": { "field": "age" } } }, "size": 0}复杂聚合
按照年龄聚合,并且请求这些年龄段的这些人的平均薪资
(子聚合)
GET bank/_search{ "query": { "match_all": {} }, "aggs": { "ageAgg": { "terms": { "field": "age", "size": 100 }, "aggs": { "ageAvg": { "avg": { "field": "balance" } } } } }, "size": 0}查出所有年龄分布,并且这些年龄段中M的平均薪资和F的平均薪资以及这个年龄段的总体平均薪资
GET bank/_search{ "query": { "match_all": {} }, "aggs": { "ageAgg": { "terms": { "field": "age", "size": 100 }, "aggs": { "fAvg": { "avg": { "field": "balance" } }, "genderAgg": { "terms": { "field": "gender.keyword", "size": 10 }, "aggs": { "balAvg": { "avg": { "field": "balance" } } } } } } }, "size": 0}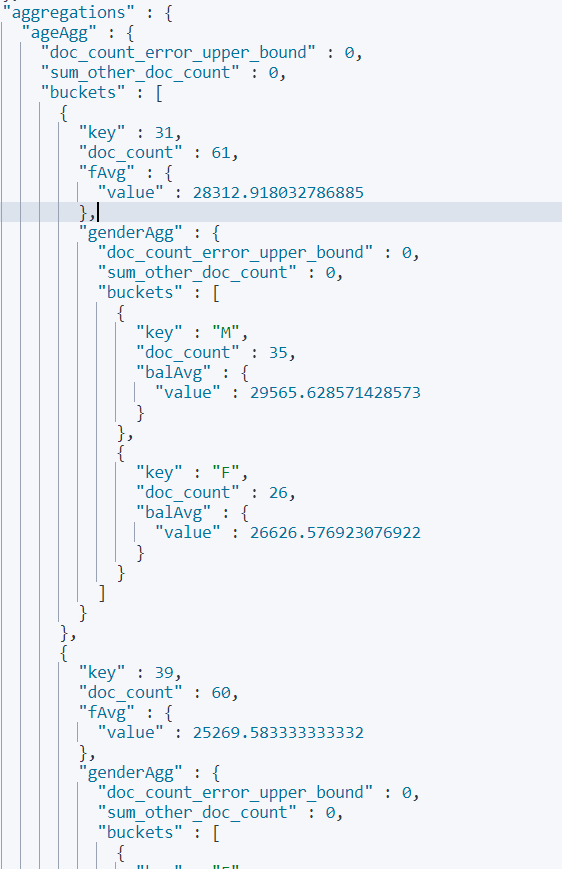
Mapping
- Mapping是用来定义一个文档(document),以及它所包含的属性(field)是如何存储索引的。比如,使用mapping来定义:
- 哪些字符串属性应该被看做全文本属性(full text fields)
- 哪些属性包含数字,日期或者地理位置
- 文档中的所有属性是否都能被索引(_all配置)
- 日期的格式
- 自定义映射规则来执行动态添加属性
6.0版本之后,移除了
type
查看映射
GET /bank/_mapping
分词
一个
tokenizer(分词器)接受一个字符流,将之分割为独立的tokens(词元,通常是独立的单词),然后输出tokens流。例如,
whitespacetokenizer遇到空白字符时分割文本。它会将文本"Quick brown fox!"分割为[Quick,brown,fox!]该
tokenizer(分词器)还负责记录各个term(词条)的顺序或position位置(用于phrase短语和word proximity词近邻查询),以及term(词条)所代表的的原始word(单词)的开始和结束的字符偏移量(character offsets)用于高亮显示搜索的内容ElasticSearch 提供了很多内置的分词器,可以用来构建 custom analyzers(自定义分词器)
安装ik分词器
下载地址 7.6.1
进入容器内部 plugins目录 或者宿主机的挂载目录
- 解压下载的文件
- 删除压缩包
- 修改目录名字为 ik
重启es,并验证是否安装成功
进入容器 /bin 目录下执行
elasticsearch-plugin list
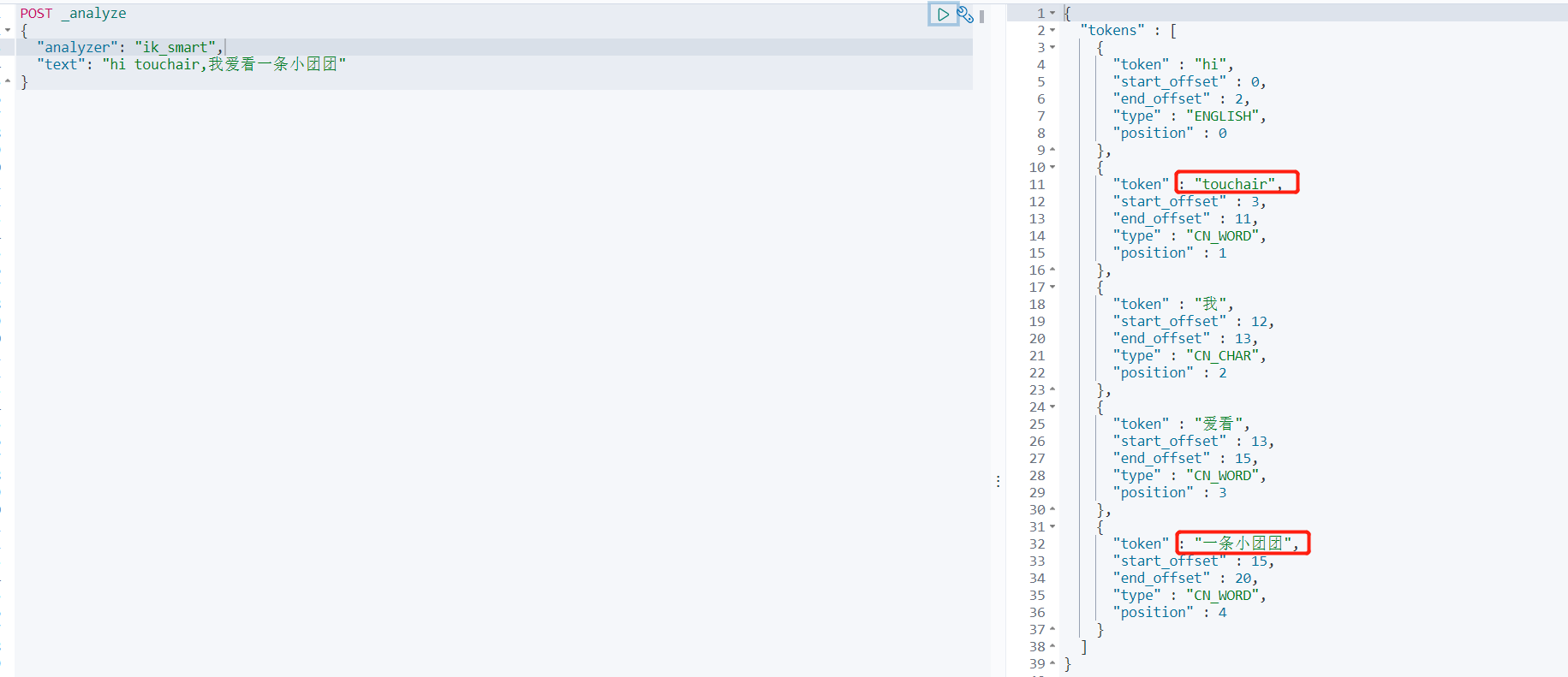
测试分词
ik_smart最少切分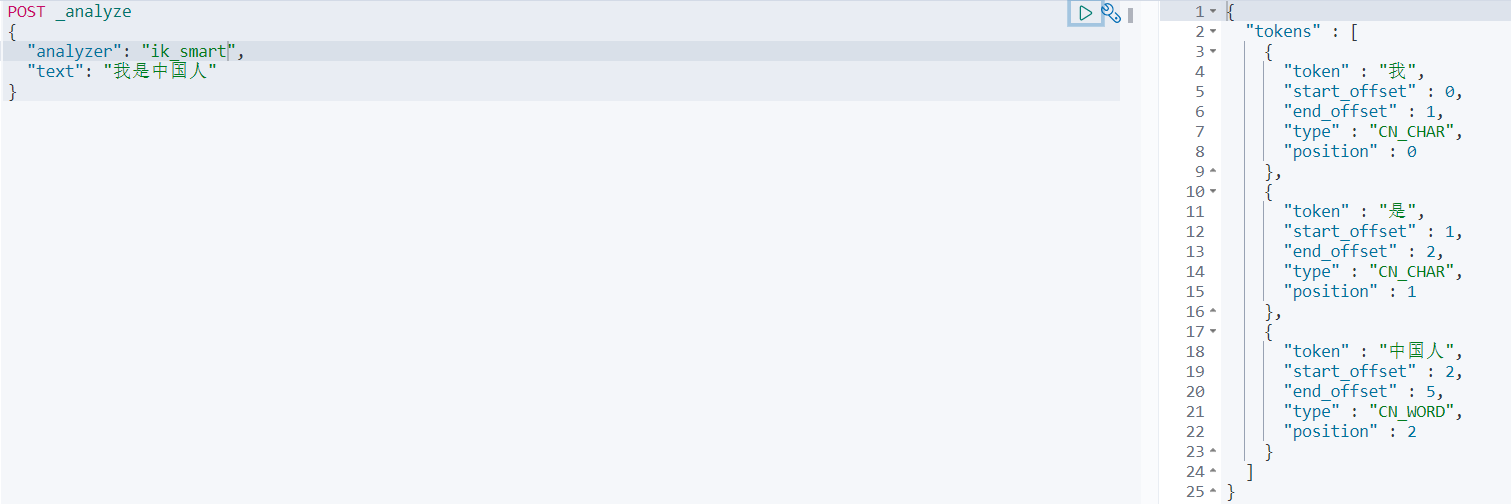
ik_max_word最细力度划分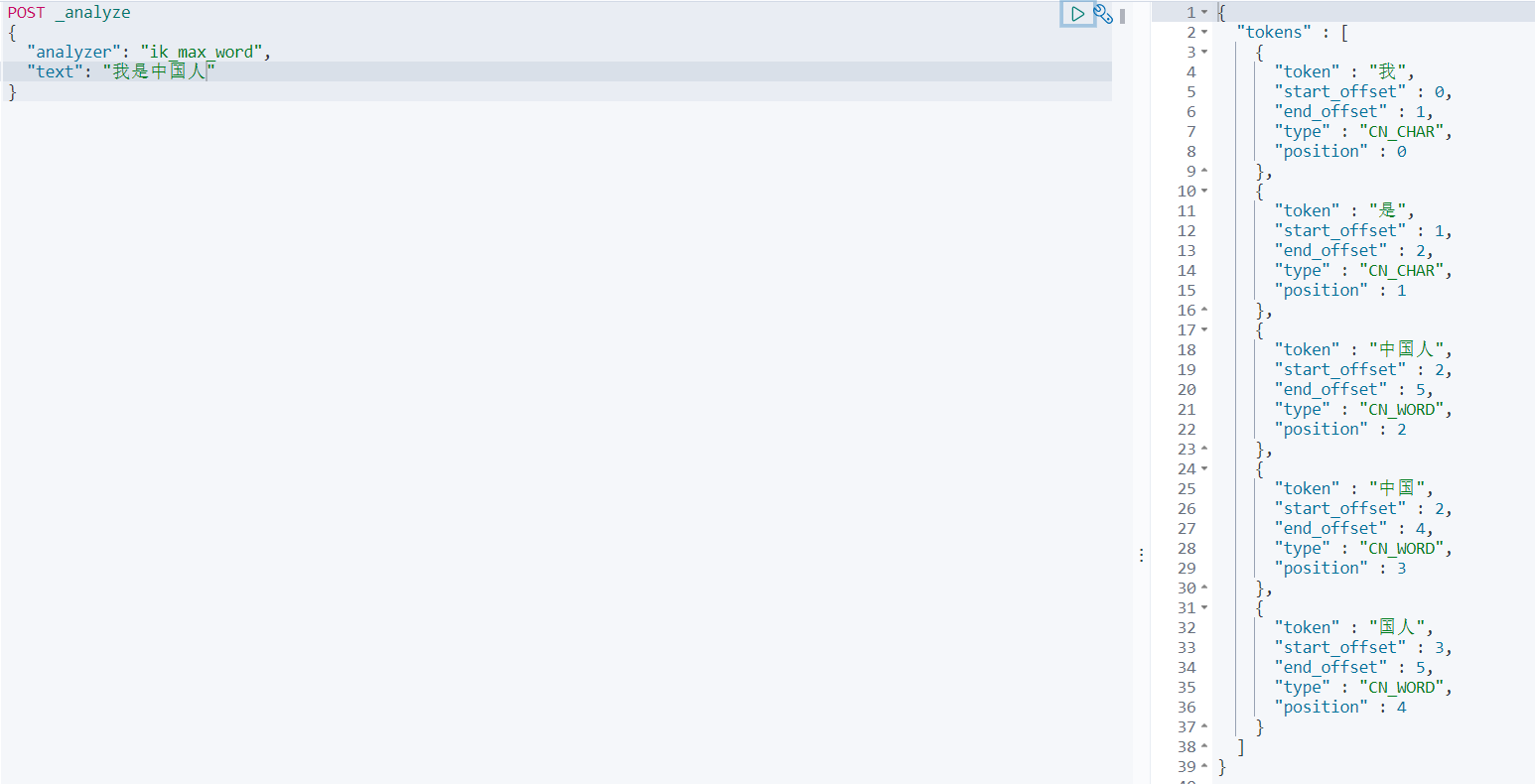
安装Nginx
拉取镜像
docker pull nginx先随便启动一个nginx实例,只是为了复制配置,方便挂载
#启动docker run -p 80:80 --name nginx -d nginx#将容器内的配置文件拷贝到当前目录 我这里是在 /var/touchAirMallVolume 目录下执行的docker container cp nginx:/etc/nginx .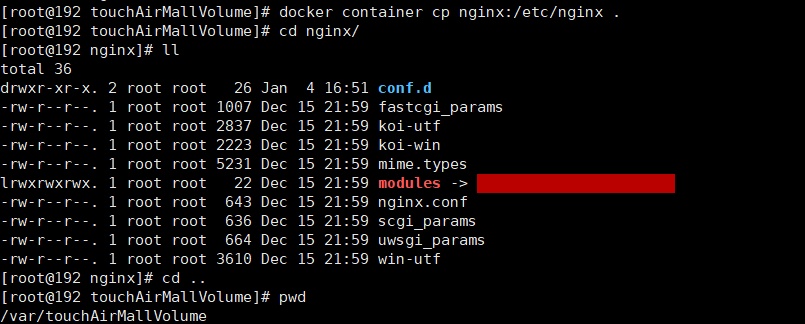
修改目录
mv nginx confmkdir nginxmv conf nginx/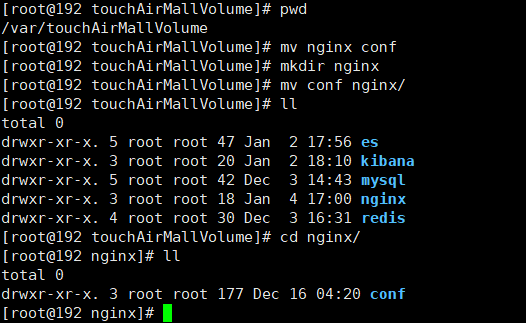
删除旧的容器,重新挂载启动
#删除旧容器docker rm -f nginx#挂载启动docker run -d --name nginx \-p 80:80 --restart=always \-v /var/touchAirMallVolume/nginx/html:/usr/share/nginx/html \-v /var/touchAirMallVolume/nginx/logs:/var/log/nginx \-v /var/touchAirMallVolume/nginx/conf:/etc/nginx \nginx验证nginx
进入宿主机nginx下的html目录,创建一个简单的html
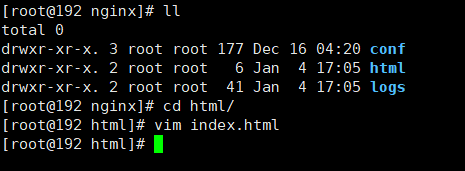

在 nginx/html/ 新增es目录,创建远程词库
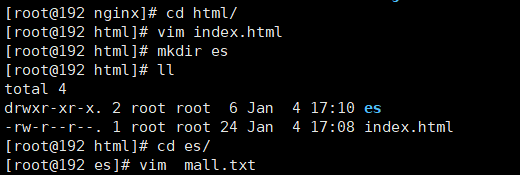

自定义扩展词库
前提:安装好nginx
修改ik分词器的 IKAnalyzer.cfg.
cd /var/touchAirMallVolume/es/plugins/ik/configvim IKAnalyzer.cfg.
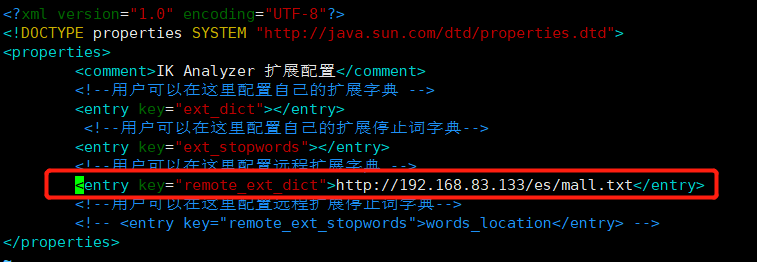
重启es容器,并测试自定义分词效果
Elasticsearch-Rest_Client
官方RestClient,封装了ES操作,API层次分明,上手简单
最终选择Elasticsearch-Rest_Client(elasticsearch-rest-high-level-client)
官方地址
如果你使用的es版本有对应的spring-data-elasticsearch,建议参照官网使用,封装了更简易的API
spring-data
springboot整合
导包(对应版本)
<dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>elasticsearch-rest-high-level-client</artifactId> <version>7.6.2</version></dependency>
配置
配置类 (全部参照官方文档)
elasticsearch-rest-high-level-client配置类
MallElasticSearchConfig
@Configurationpublic class MallElasticSearchConfig { public static final RequestOptions COMMON_OPTIONS; static { RequestOptions.Builder builder = RequestOptions.DEFAULT.toBuilder();// builder.addHeader("Authorization", "Bearer " + TOKEN);// builder.setHttpAsyncResponseConsumerFactory(// new HttpAsyncResponseConsumerFactory// .HeapBufferedResponseConsumerFactory(30 * 1024 * 1024 * 1024)); COMMON_OPTIONS = builder.build(); } @Bean public RestHighLevelClient esRestClient() { RestHighLevelClient client = new RestHighLevelClient( RestClient.builder( new HttpHost("192.168.83.133", 9200, "http"))); return client; }}
使用
mall-search单元测试测试是否注入成功
@Resource private RestHighLevelClient restHighLevelClient; @Test public void test() { System.out.println(restHighLevelClient); }测试存储(更新)数据到es
/** * 测试存储数据到es * 更新也可以 */ @Test public void testSave() throws IOException { IndexRequest indexRequest = new IndexRequest("users"); indexRequest.id("1");// indexRequest.source("username", "ZhSan", "age", 18, "gender","男"); User user = new User(); user.setUserName("ZhSan"); user.setGender("男"); user.setAge(18); String jsonStr = JSONUtil.toJsonStr(user); indexRequest.source(jsonStr, XContentType.JSON);//要保存的内容 //执行操作 IndexResponse index = restHighLevelClient.index(indexRequest, MallElasticSearchConfig.COMMON_OPTIONS); System.out.println(index); } @Data class User{ private String userName; private Integer age; private String gender; }测试复杂检索
/** * 复杂检索 */ @Test public void searchData() throws IOException { //1、创建检索请求 SearchRequest searchRequest = new SearchRequest(); //2、指定索引 searchRequest.indices("bank"); //3、指定DSL,检索条件 SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); //3.1、构造检索条件 //searchSourceBuilder.query(); //searchSourceBuilder.from(); //searchSourceBuilder.size(); //searchSourceBuilder.aggregation(); searchSourceBuilder.query(QueryBuilders.matchQuery("address", "mill")); //聚合操作 //按照年龄的值分布进行聚合 TermsAggregationBuilder ageAgg = AggregationBuilders.terms("ageAgg").field("age").size(10); searchSourceBuilder.aggregation(ageAgg); //计算平均薪资 AvgAggregationBuilder balanceAvgAgg = AggregationBuilders.avg("balanceAvgAgg").field("balance"); searchSourceBuilder.aggregation(balanceAvgAgg); System.out.println("检索条件:"+searchSourceBuilder.toString()); searchRequest.source(searchSourceBuilder); //4、执行检索 SearchResponse searchResponse = restHighLevelClient.search(searchRequest, MallElasticSearchConfig.COMMON_OPTIONS); //5、分析结果 System.out.println(searchResponse.toString()); //5.1 获取所有查到的数据 SearchHits hits = searchResponse.getHits(); SearchHit[] hitsHits = hits.getHits(); for (SearchHit searchHit : hitsHits) { /** * "_index" : "bank", * "_type" : "accout", * "_id" : "1", * "_score" : 1.0, * "_source" : {} */ String sourceAsString = searchHit.getSourceAsString(); Account account = JSON.parseObject(sourceAsString, Account.class); System.out.println(account); } //5.2 获取这次检索到的分析信息 Aggregations aggregations = searchResponse.getAggregations();// for (Aggregation aggregation : aggregations.asList()) {// System.out.println("当前聚合:"+aggregation.getName());// } Terms ageAggRes = aggregations.get("ageAgg"); for (Terms.Bucket bucket : ageAggRes.getBuckets()) { String keyAsString = bucket.getKeyAsString(); System.out.println("年龄:" + keyAsString+"===>"+bucket.getDocCount()); } Avg balanceAvgAggRes = aggregations.get("balanceAvgAgg"); System.out.println("平均薪资:" + balanceAvgAggRes.getValue()); } /** * bank 账户信息 */ @Data @ToString static class Account { private int account_number; private int balance; private String firstname; private String lastname; private int age; private String gender; private String address; private String employer; private String email; private String city; private String state; }
商品上架
spu在es中的存储模型分析
如果每个sku都存储规格参数,会有冗余存储,因为每个spu对应的sku的规格参数都一样,但是如果将规格参数单独建立索引会出现检索时出现大量数据传输的问题,会阻塞网络
因此我们选用第一种存储模型,以空间换时间
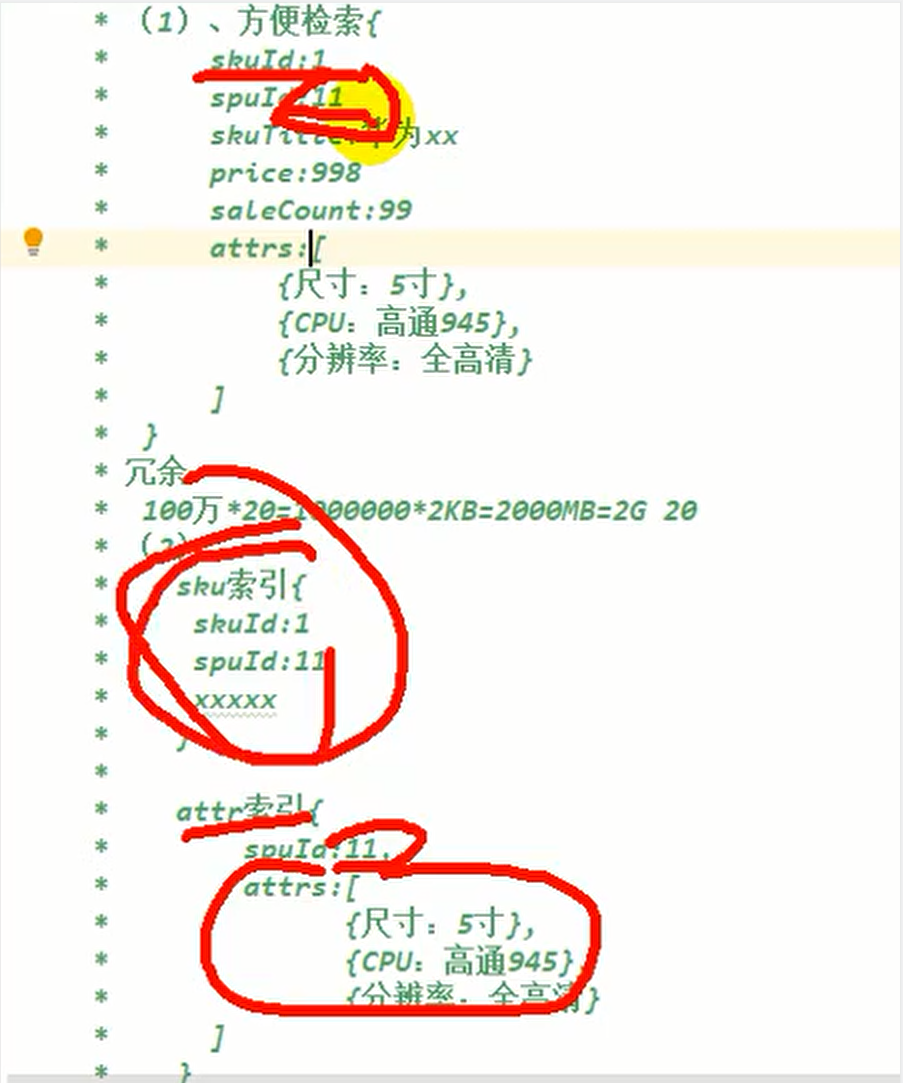
向ES添加商品属性映射
es-product 属性映射
PUT product{ "mappings": { "properties": { "skuId":{ "type":"long" }, "spuId":{ "type":"keyword" }, "skuTitle":{ "type":"text", "analyzer": "ik_smart" }, "skuPrice":{ "type":"keyword" }, "skuImg":{ "type":"keyword", "index": false, "doc_values": false }, "saleCount":{ "type":"long" }, "hasStock":{ "type":"boolean" }, "hotScore":{ "type":"long" }, "brandId":{ "type":"long" }, "catalogId":{ "type":"long" }, "brandName":{ "type":"keyword", "index": false, "doc_values": false }, "brandImg":{ "type":"keyword", "index": false, "doc_values": false }, "catalogName":{ "type":"keyword", "index": false, "doc_values": false }, "attrs":{ "type": "nested", "properties": { "attrId":{ "type":"long" }, "attrName":{ "type":"keyword", "index": false, "doc_values": false }, "attrValue":{ "type":"keyword" } } } } }}
商品上架功能实现
实现方法
com.touch.air.mall.product.service.impl.SpuInfoServiceImpl.up()
Feign调用流程
- 问题思考:远程调用失败 是否会重复调用?接口幂等性;重试机制?
构造请求数据,将对象转为json
#源码RequestTemplate template=buildTemplateFromArgs.create(argv)发送请求进行执行(执行成功会解码响应数据)
executeAndDecode(template)执行请求会有重试机制
while(true){ try{ executeAndDecode(template); }catch(){ try{retryer.continueOrPropagate(e);}catch(){throw ex;} continue; }}
商城首页
动静分离
整体架构
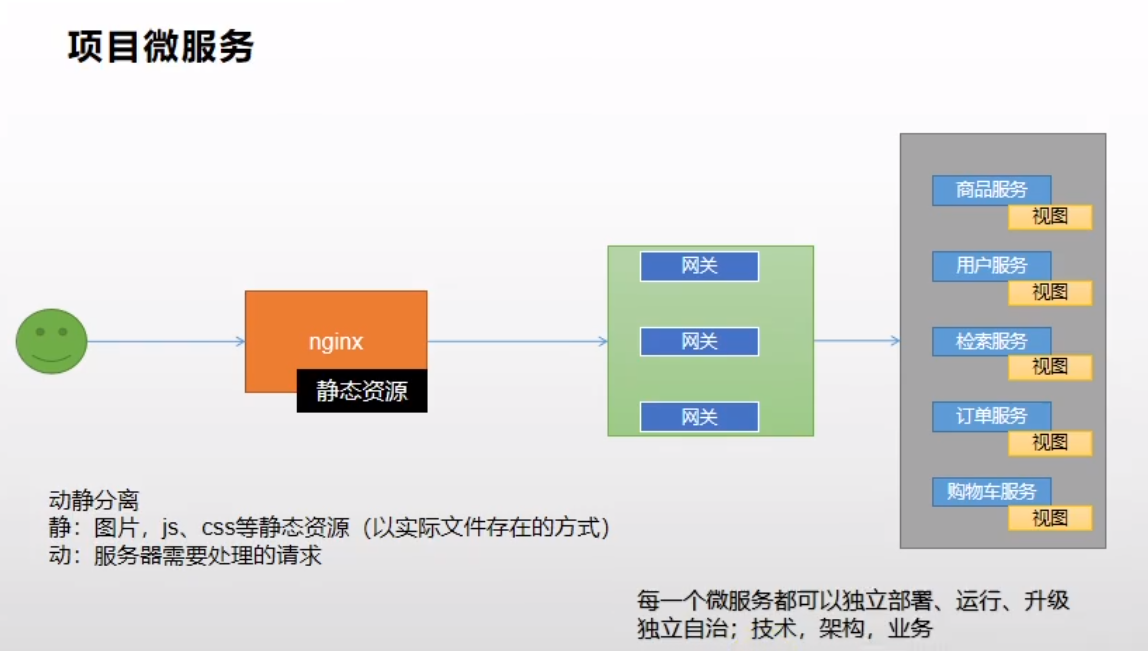
整合thymeleaf渲染首页
添加依赖
<!--模板引擎 thymeleaf--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-thymeleaf</artifactId> </dependency>导入静态资源 --首页资源
index文件夹 添加到商品微服务的
resources/static下index.html文件添加到商品微服务的resources/templates下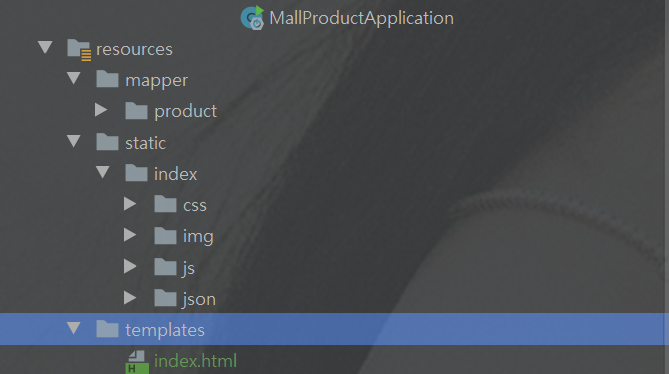
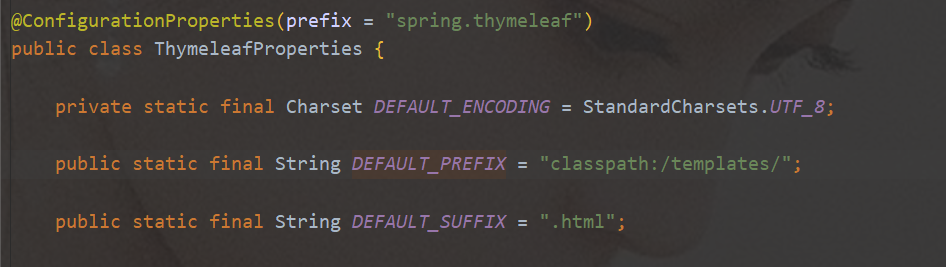
application.yml添加配置静态资源都放在static文件夹下就可以按照路径直接访问
页面放在templates下,直接访问 SpringBoot,访问项目的时候,默认会找index.html
#页面测试#访问静态资WebMvcAutoConfiguration源码OrderedHiddenHttpMethodFilter处理页面发送的rest请求InternalResourceViewResolver视图解析器进行拼串(前缀、后缀)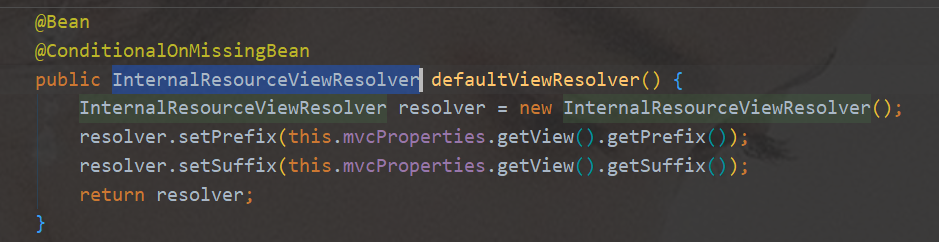
addResourceHandlers资源处理器WelcomePageHandlerMapping欢迎页 默认静态资源路径、默认加载index.html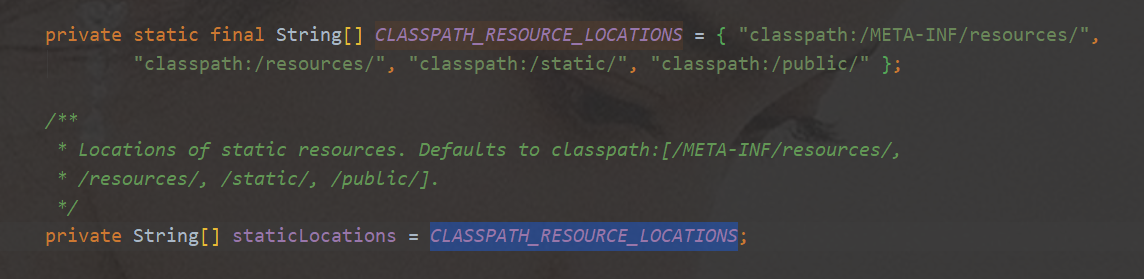
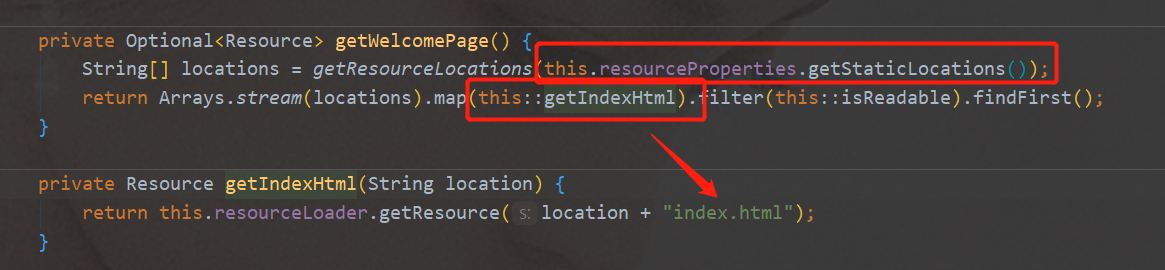
文档
thymeleaf官方文档
页面修改不重启服务实时更新
引入
dev-tools<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-devtools</artifactId> <optional>true</optional> </dependency>修改完页面 直接
ctrl+shift+F9重新自动编译,如果修改了代码配置,推荐重启 避免bug
渲染一级分类数据
接口
com.touch.air.mall.product.web.IndexController.indexPage#请求ur id="渲染二级三级分类数据">渲染二级&三级分类数据接口
com.touch.air.mall.product.web.IndexController.getCatalogJson#请求ur src="https://img2020.cnblogs.com/blog/1875400/202101/1875400-20210112100007486-921487636.png" alt="image-20210108104305308" loading="lazy">
nginx搭建域名访问环境
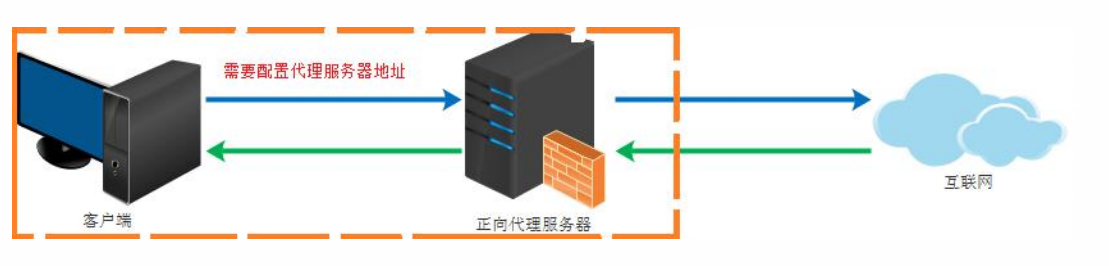
正向代理与反向代理
正向代理:如上网,隐藏客户端信息(常见VPN)
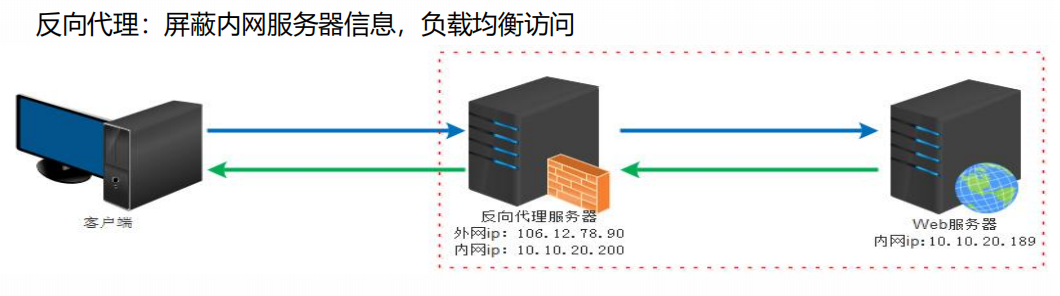
反向代理:屏蔽内网服务器信息,负载均衡访问
nginx+Windows搭建域名访问环境
windows
windows hosts文件
C:\Windows\System32\drivers\etc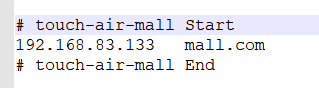
修改完成后,使用域名访问ES测试
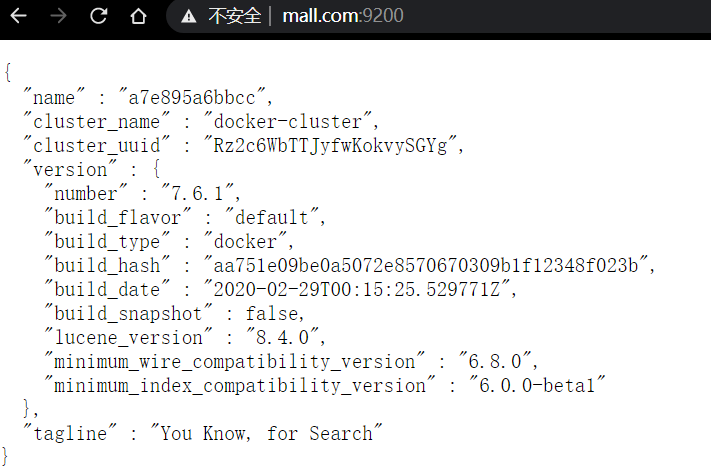
nginx进行反向代理
nginx配置文件
conf/nginx.conf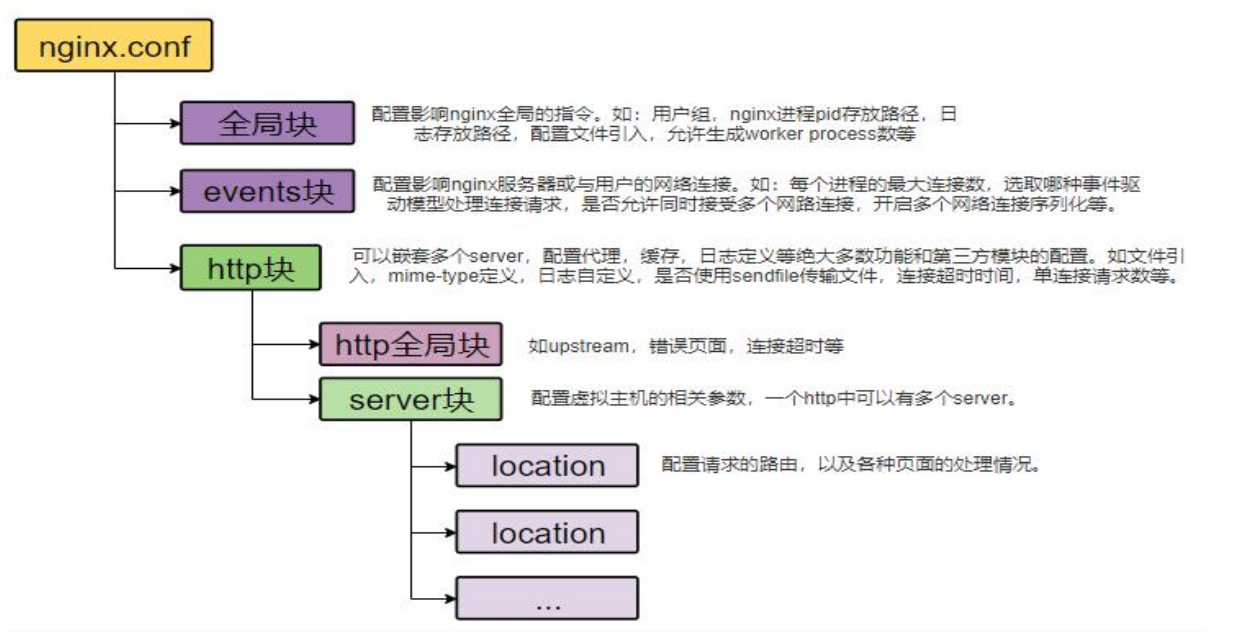
nginx.conf 表面所有的server块所在的位置
nginx/conf.d 目录下的 default.conf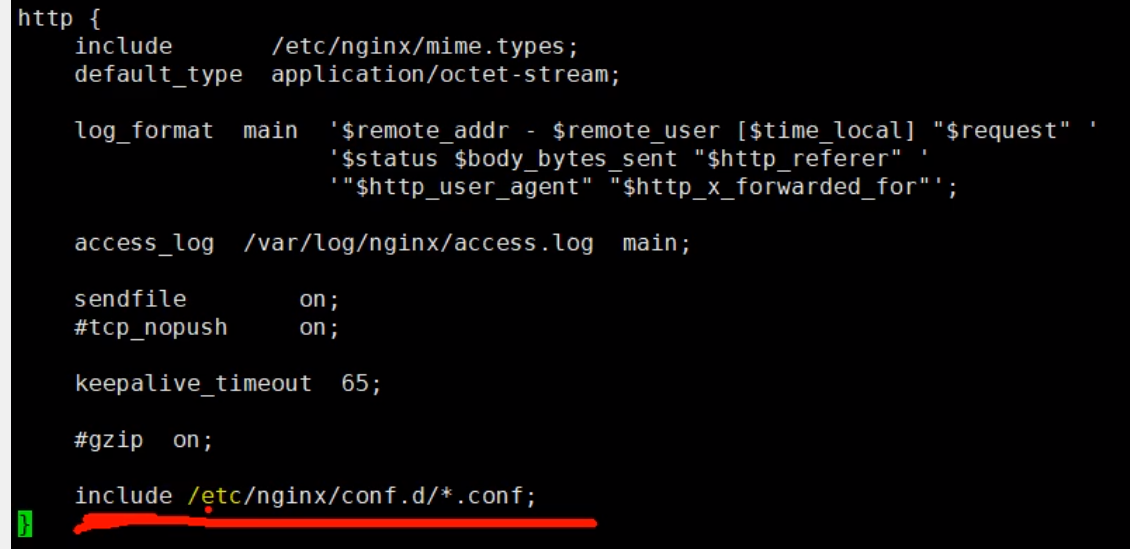
将所有来自mall.com的请求,都转到商品服务
cp nginx/conf.d 目录下的default.conf mall.confvim mall.conf指定server_name 为 mall.com (与页面请求的Host对应)配置转发的地址 本地商品服务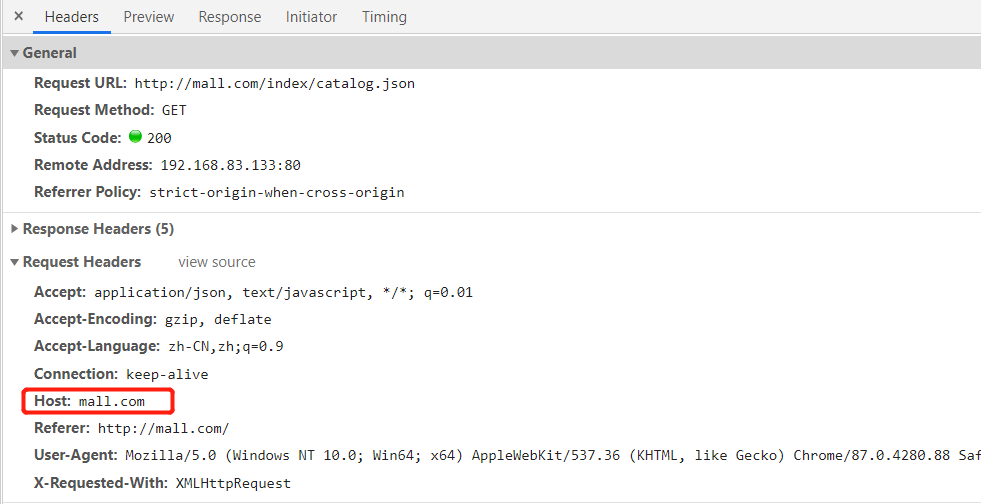
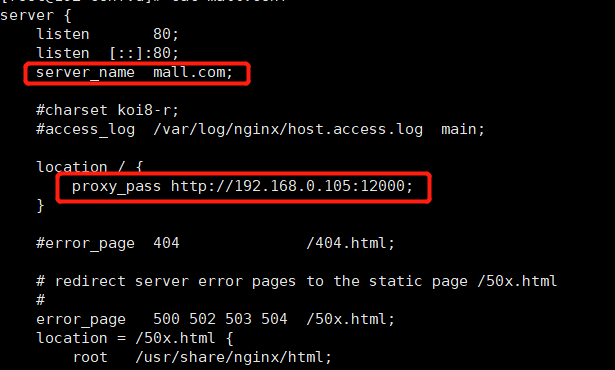
- 重启nginx容器
- 此时页面访问
mall.com,会展示商城首页
域名访问,负载均衡到网关
nginx官网
使用nginx 在http协议中负载均衡
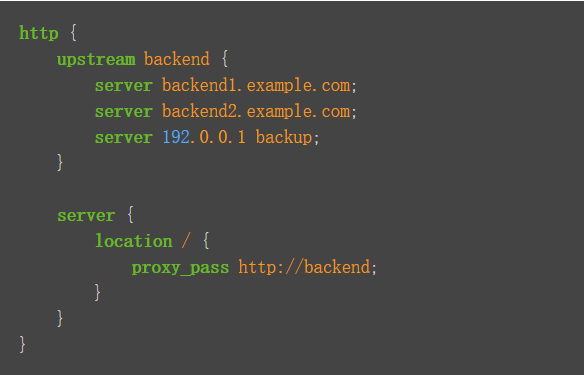
修改
nginx.conf#添加上游服务器的服务地址#转交给本地网关upstream mall { server 192.168.0.105:9527; }修改
nginx/conf.d目录下的mall.conf#对应上游服务器的名字location / { proxy_pass }
注意:nginx代理到网关的时候,会默认丢掉很多信息,包括host信息等。在这里如果没有host信息,网关路由将匹配不到,也就无法转发到指定的服务
修改配置,让nginx保存host
vim mall.conf#添加以下配置proxy_set_header Host $host重启nginx容器
添加网关路由处理规则
#配置在vue路由的最下面- id: mall_host uri: lb://touch-air-mall-product predicates: - Host=**.mall.com重启网关服务
浏览器输入 mall.com 访问成功
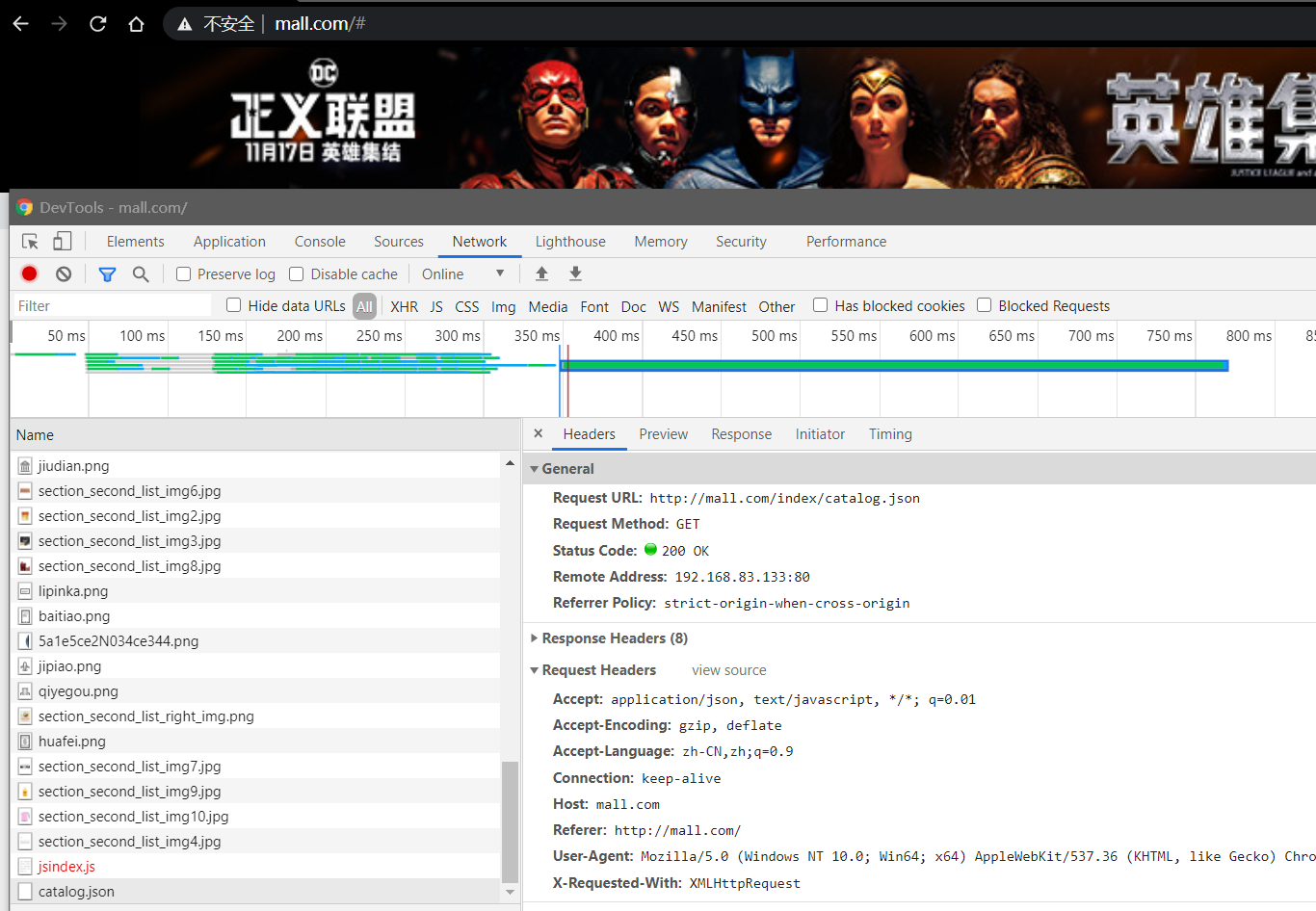
最终域名映射效果
- 请求接口 mall.com
- 请求页面 mall.com
- nginx 直接代理给网关,网关进行判断
- 如果/api/**,转交给对应的服务器
- 如果是满足域名,转交给对应的服务
原文转载:http://www.shaoqun.com/a/508507.html
c88:https://www.ikjzd.com/w/1017.html
parenthood:https://www.ikjzd.com/w/2497
分布式高级篇(一)ElasticSearch和商城首页ElasticSearch--全文检索简介是什么ElasticSearch是一个分布式的开源搜索和分析引擎,适用于所有类型的数据,包括文本、数字、地理空间、结构化和非结构化数据ElasticSearch在ApacheLucene的基础上开发而成,由Elastic于2010年首次发布,ElasticSearch以其简单的REST风格API、分布式
f2c:f2c
zappos.com:zappos.com
亚马逊瑞典站确认开通 他们的目标是北欧:亚马逊瑞典站确认开通 他们的目标是北欧
四川乐山大佛在哪里?四川乐山大佛好玩吗?:四川乐山大佛在哪里?四川乐山大佛好玩吗?
OrderPlus(西安澳鹏网络)近期完成了1亿元B轮融资!:OrderPlus(西安澳鹏网络)近期完成了1亿元B轮融资!
No comments:
Post a Comment