欢迎访问我的GitHub
https://github.com/zq2599/blog_demos
内容:所有原创文章分类汇总及配套源码,涉及Java、Docker、Kubernetes、DevOPS等;
本篇概览
- 本文是《hive学习笔记》系列的第十一篇,截至目前,一进一出的UDF、多进一出的UDAF咱们都学习过了,最后还有一进多出的UDTF留在本篇了,这也是本篇的主要内容;
- 一进多出的UDTF,名为用户自定义表生成函数(User-Defined Table-Generating Functions, UDTF);
- 前面的文章中,咱们曾经体验过explode就是hive内置的UDTF:
hive> select explode(address) from t3;OKprovince guangdongcity shenzhenprovince jiangsucity nanjingTime taken: 0.081 seconds, Fetched: 4 row(s)- 本篇的UDTF一共有两个实例:把一列拆成多列、把一列拆成多行(每行多列);
- 接下来开始实战;
源码下载
- 如果您不想编码,可以在GitHub下载所有源码,地址和链接信息如下表所示:
| 名称 | 链接 | 备注 |
|---|---|---|
| 项目主页 | https://github.com/zq2599/blog_demos | 该项目在GitHub上的主页 |
| git仓库地址(https) | https://github.com/zq2599/blog_demos.git | 该项目源码的仓库地址,https协议 |
| git仓库地址(ssh) | git@github.com:zq2599/blog_demos.git | 该项目源码的仓库地址,ssh协议 |
- 这个git项目中有多个文件夹,本章的应用在hiveudf文件夹下,如下图红框所示:
准备工作
为了验证UDTF的功能,咱们要先把表和数据都准备好:
- 新建名为t16的表:
create table t16(person_name string,string_field string)row format delimited fields terminated by '|'stored as textfile;- 本地新建文本文件016.txt,内容如下:
tom|1:province:guangdongjerry|2:city:shenzhenjohn|3- 导入数据:
load data local inpath '/home/hadoop/temp/202010/25/016.txt' overwrite into table t16;- 数据准备完毕,开始编码;
UDTF开发的关键点
- 需要继承GenericUDTF类;
- 重写initialize方法,该方法的入参只有一个,类型是StructObjectInspector,从这里可以取得UDTF作用了几个字段,以及字段类型;
- initialize的返回值是StructObjectInspector类型,UDTF生成的每个列的名称和类型都设置到返回值中;
- 重写process方法,该方法中是一进多出的逻辑代码,把每个列的数据准备好放在数组中,执行一次forward方法,就是一行记录;
- close方法不是必须的,如果业务逻辑执行完毕,可以将释放资源的代码放在这里执行;
- 接下来,就按照上述关键点开发UDTF;
一列拆成多列
- 接下来要开发的UDTF,名为udf_wordsplitsinglerow,作用是将入参拆分成多个列;
- 下图红框中是t16表的一条原始记录的string_field字段,会被udf_wordsplitsinglerow处理:
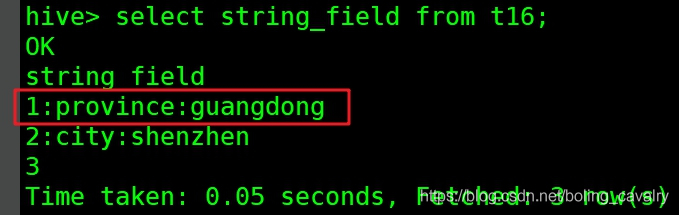
- 上面红框中的字段被UDTF处理处理后,一列变成了三列,每一列的名称如下图黄框所示,每一列的值如红框所示:
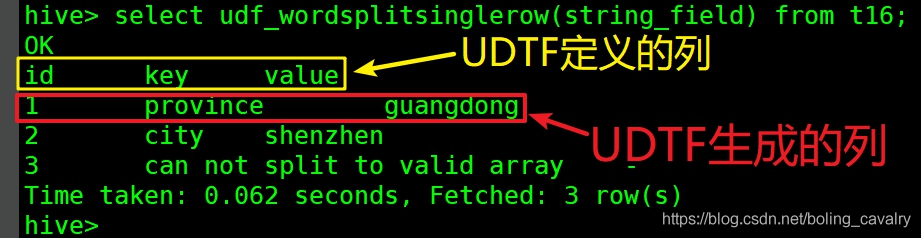
- 以上就是咱们马上就要开发的功能;
- 打开前文创建的hiveudf工程,新建WordSplitSingleRow.java:
package com.bolingcavalry.hiveudf.udtf;import org.apache.commons.lang.StringUtils;import org.apache.hadoop.hive.ql.exec.UDFArgumentException;import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;import org.apache.hadoop.hive.ql.metadata.HiveException;import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;import org.apache.hadoop.hive.serde2.objectinspector.*;import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector.Category;import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;import java.util.ArrayList;import java.util.List;/** * @Description: 把指定字段拆成多列 * @author: willzhao E-mail: zq2599@gmail.com * @date: 2020/11/5 14:43 */public class WordSplitSingleRow extends GenericUDTF { private PrimitiveObjectInspector stringOI = null; private final static String[] EMPTY_ARRAY = {"NULL", "NULL", "NULL"}; /** * 一列拆成多列的逻辑在此 * @param args * @throws HiveException */ @Override public void process(Object[] args) throws HiveException { String input = stringOI.getPrimitiveJavaObject(args[0]).toString(); // 无效字符串 if(StringUtils.isBlank(input)) { forward(EMPTY_ARRAY); } else { // 分割字符串 String[] array = input.split(":"); // 如果字符串数组不合法,就返回原始字符串和错误提示 if(null==array || array.length<3) { String[] errRlt = new String[3]; errRlt[0] = input; errRlt[1] = "can not split to valid array"; errRlt[2] = "-"; forward(errRlt); } else { forward(array); } } } /** * 释放资源在此执行,本例没有资源需要释放 * @throws HiveException */ @Override public void close() throws HiveException { } @Override public StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException { List<? extends StructField> inputFields = argOIs.getAllStructFieldRefs(); // 当前UDTF只处理一个参数,在此判断传入的是不是一个参数 if (1 != inputFields.size()) { throw new UDFArgumentLengthException("ExplodeMap takes only one argument"); } // 此UDTF只处理字符串类型 if(!Category.PRIMITIVE.equals(inputFields.get(0).getFieldObjectInspector().getCategory())) { throw new UDFArgumentException("ExplodeMap takes string as a parameter"); } stringOI = (PrimitiveObjectInspector)inputFields.get(0).getFieldObjectInspector(); //列名集合 ArrayList<String> fieldNames = new ArrayList<String>(); //列对应的value值 ArrayList<ObjectInspector> fieldOIs = new ArrayList<ObjectInspector>(); // 第一列的列名 fieldNames.add("id"); // 第一列的inspector类型为string型 fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector); // 第二列的列名 fieldNames.add("key"); // 第二列的inspector类型为string型 fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector); // 第三列的列名 fieldNames.add("value"); // 第三列的inspector类型为string型 fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector); return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames, fieldOIs); }}- 上述代码中的重点是process方法,取得入参后用冒号分割字符串,得到数组,再调用forward方法,就生成了一行记录,该记录有三列;
验证UDTF
接下来将WordSplitSingleRow.java部署成临时函数并验证;
- 编码完成后,在pom.
- 在target目录得到文件hiveudf-1.0-SNAPSHOT.jar
- 将jar下载到hive服务器,我这里放在此目录:/home/hadoop/udf/
- 在hive会话模式执行以下命令添加本地jar:
add jar /home/hadoop/udf/hiveudf-1.0-SNAPSHOT.jar;- 部署临时函数:
create temporary function udf_wordsplitsinglerow as 'com.bolingcavalry.hiveudf.udtf.WordSplitSingleRow';- 执行以下SQL验证:
select udf_wordsplitsinglerow(string_field) from t16;- 结果如下,可见每一行记录的string_field字段都被分割成了id、key、value三个字段:
hive> select udf_wordsplitsinglerow(string_field) from t16;OKid key value1 province guangdong2 city shenzhen3 can not split to valid array -Time taken: 0.066 seconds, Fetched: 3 row(s)关键点要注意
- 值得注意的是,UDTF不能和其他字段同时出现在select语句中,例如以下的SQL会执行失败:
select person_name,udf_wordsplitsinglerow(string_field) from t16;- 错误信息如下:
hive> select person_name,udf_wordsplitsinglerow(string_field) from t16;FAILED: SemanticException [Error 10081]: UDTF's are not supported outside the SELECT clause, nor nested in expressions- 如果希望得到UDTF和其他字段的结果,可以使用LATERAL VIEW语法,完整SQL如下:
select t.person_name, udtf_id, udtf_key, udtf_valuefrom ( select person_name, string_field from t16) t LATERAL VIEW udf_wordsplitsinglerow(t.string_field) v as udtf_id, udtf_key, udtf_value;- 查询结果如下,可见指定字段和UDTF都能显示:
hive> select t.person_name, udtf_id, udtf_key, udtf_value > from ( > select person_name, string_field > from t16 > ) t LATERAL VIEW udf_wordsplitsinglerow(t.string_field) v as udtf_id, udtf_key, udtf_value;OKt.person_name udtf_id udtf_key udtf_valuetom 1 province guangdongjerry 2 city shenzhenjohn 3 can not split to valid array -Time taken: 0.122 seconds, Fetched: 3 row(s)一列拆成多行(每行多列)
- 前面咱们试过了将string_field字段拆分成id、key、value三个字段,不过拆分后总行数还是不变,接下来的UDTF,是把string_field拆分成多条记录,然后每条记录都有三个字段;
- 需要导入新的数据到t16表,新建文本文件016_multi.txt,内容如下:
tom|1:province:guangdong,4:city:yangjiangjerry|2:city:shenzhenjohn|3- 在hive会话窗口执行以下命令,会用016_multi.txt的内容覆盖t16表已有内容:
load data local inpath '/home/hadoop/temp/202010/25/016_multi.txt' overwrite into table t16;- 此时的数据如下图所示,红框中是一条记录的string_field字段值,咱们接下来要开发的UDTF,会先用逗号分隔,得到的就是1:province:guangdong和4:city:yangjiang这两个字符串,接下来对每个字符串用冒号分隔,就会得到两条id、key、value这样的记录,也就是多行多列:
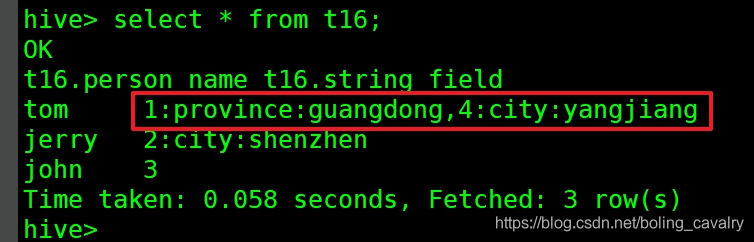
- 预期中的UDTF结果如下图所示,红框和黄框这两条记录都来自一条记录的string_field字段值:
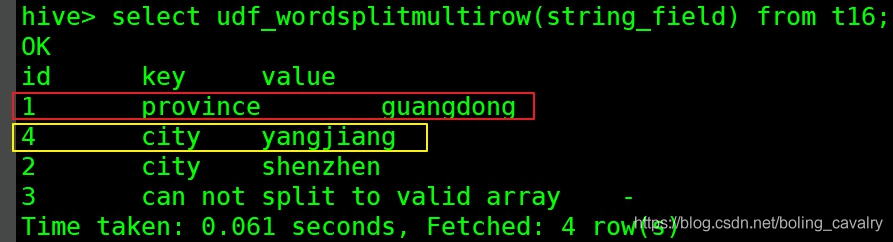
- 接下来开始编码,新建WordSplitMultiRow.java,代码如下,可见和WordSplitSingleRow的差异仅在process方法,WordSplitMultiRow的process中执行了多次forward,因此有了多条记录:
package com.bolingcavalry.hiveudf.udtf;import org.apache.commons.lang.StringUtils;import org.apache.hadoop.hive.ql.exec.UDFArgumentException;import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;import org.apache.hadoop.hive.ql.metadata.HiveException;import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;import org.apache.hadoop.hive.serde2.objectinspector.*;import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector.Category;import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;import java.util.ArrayList;import java.util.List;/** * @Description: 把指定字段拆成多行,每行有多列 * @author: willzhao E-mail: zq2599@gmail.com * @date: 2020/11/5 14:43 */public class WordSplitMultiRow extends GenericUDTF { private PrimitiveObjectInspector stringOI = null; private final static String[] EMPTY_ARRAY = {"NULL", "NULL", "NULL"}; /** * 一列拆成多列的逻辑在此 * @param args * @throws HiveException */ @Override public void process(Object[] args) throws HiveException { String input = stringOI.getPrimitiveJavaObject(args[0]).toString(); // 无效字符串 if(StringUtils.isBlank(input)) { forward(EMPTY_ARRAY); } else { // 用逗号分隔 String[] rowArray = input.split(","); // 处理异常 if(null==rowArray || rowArray.length<1) { String[] errRlt = new String[3]; errRlt[0] = input; errRlt[1] = "can not split to valid row array"; errRlt[2] = "-"; forward(errRlt); } else { // rowArray的每个元素,都是"id:key:value"这样的字符串 for(String singleRow : rowArray) { // 要确保字符串有效 if(StringUtils.isBlank(singleRow)) { forward(EMPTY_ARRAY); } else { // 分割字符串 String[] array = singleRow.split(":"); // 如果字符串数组不合法,就返回原始字符串和错误提示 if(null==array || array.length<3) { String[] errRlt = new String[3]; errRlt[0] = input; errRlt[1] = "can not split to valid array"; errRlt[2] = "-"; forward(errRlt); } else { forward(array); } } } } } } /** * 释放资源......原文转载:http://www.shaoqun.com/a/864383.html
跨境电商:https://www.ikjzd.com/
paipaiwang:https://www.ikjzd.com/w/2205
c79:https://www.ikjzd.com/w/1016
ishare:https://www.ikjzd.com/w/2308
欢迎访问我的GitHubhttps://github.com/zq2599/blog_demos内容:所有原创文章分类汇总及配套源码,涉及Java、Docker、Kubernetes、DevOPS等;本篇概览本文是《hive学习笔记》系列的第十一篇,截至目前,一进一出的UDF、多进一出的UDAF咱们都学习过了,最后还有一进多出的UDTF留在本篇了,这也是本篇的主要内容;一进多出的UDTF,名为用户
wario:https://www.ikjzd.com/w/887
CPM达5.3美元?12个统计数据,预示2021年Facebook外贸营销策略新变化:https://www.ikjzd.com/articles/142323
Tiktok有望全面上线购物直通车:https://www.ikjzd.com/articles/142324
亚马逊卖家修改品牌不成功?试试这些方法:https://www.ikjzd.com/articles/142312
亚马逊卖家遇到差评review,应该从哪些方面进行分析:https://www.ikjzd.com/articles/142321
寂寞少妇姿势销魂 我疯狂高潮:http://lady.shaoqun.com/a/104743.html
小舅子媳妇用胸撩拨 与我激情缠绵(2/2):http://lady.shaoqun.com/a/49359.html
岳让我扒她内裤 岳用手握着我的那个:http://www.30bags.com/m/a/249858.html
这位仍然和父母住在一起的丝绸男是如何成为福布斯最富有的女人的:http://lady.shaoqun.com/a/414026.html
一晚上辛苦三次,谁受得了?为什么治疗前列腺的药物会导致阴茎异常勃起:http://lady.shaoqun.com/a/414027.html
19岁那年,她和一个亿万富翁约会,买了一艘游艇过着奢华的生活。她有这7个为富人钓鱼的步骤!:http://lady.shaoqun.com/a/414028.html
女人暗恋一个男人,这些眼神和表情是藏不住的:http://lady.shaoqun.com/a/414029.html
No comments:
Post a Comment